In the previous part of this series, we looked at an intuitive explanation of attention mechanisms and how to determine relevance between two feature vectors. Next, we classify attention mechanisms and study the types in detail.
Categorisation of Attention
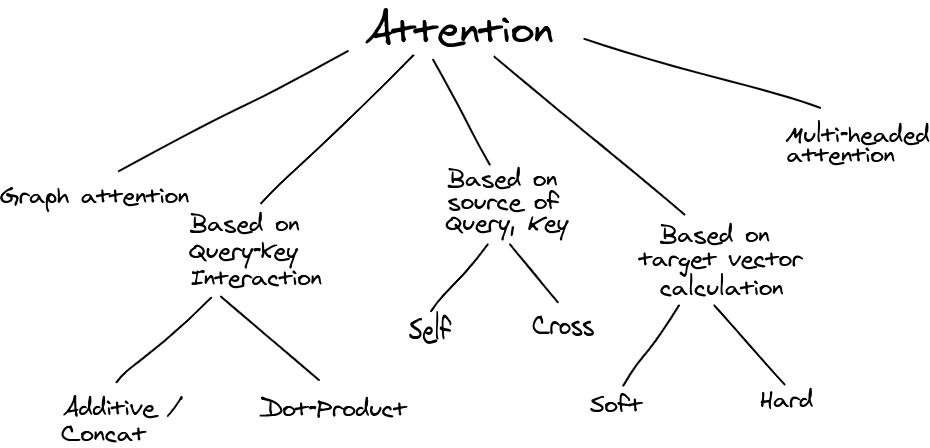
Self-Attention and Cross-Attention
Self and Cross are loosely defined terms associated to the attention mechanisms when the query and the key, value pair are obtained from the same and different “sources” respectively.
Self-Attention: An Overview

Let’s say we have a bunch of feature vectors to represent an entity such as a sentence or an image. Self-attention can be thought of as making each of the feature vectors in this bunch “aware” of the others. The representation of each input feature vector obtained after a self-attention mechanism applied on the inputs can be termed as the contextual representation of the input.
Self-Attention in Different Settings
Understanding what self attention is doesn’t bring things into perspective, how self attention mechanism is utilised in various settings is something that we need to study. Let’s dive in.
Self-Attention in Sentences
Consider a sentence, “John used a bat to hit a six.” We can use a self-attention mechanism to find a contextual representation of each of the word in this sentence. The input to the self-attention method is a sequence of word embeddings representing the sequence of words in this sentence. Let’s try to demystify, how can we obtain a contextual representation for the word “bat.”
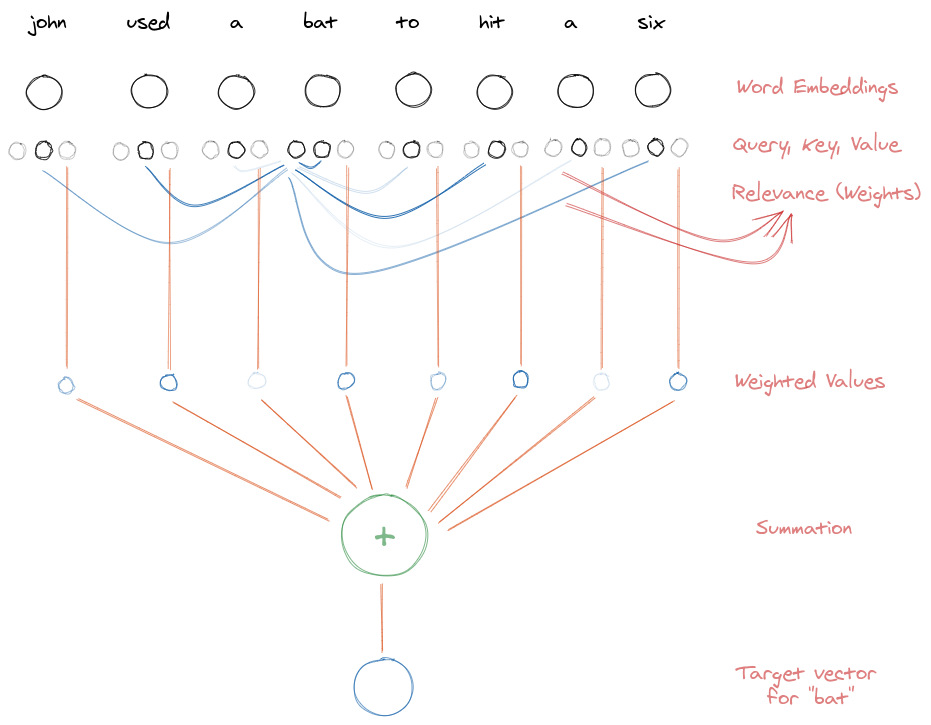
Firstly, the word embeddings are projected into respective query, key and value triplets. The projection matrices are shared across words, allowing sequences of varying lengths. The query of the word \(bat\) interacts with the key of each of the words (including \(bat\) itself) to find the relevance of \(bat\) with all the words in the sequence. The relevance is a single number between 0 and 1 (after the softmax operation). Usually, a weighted sum (where weights = relevances) of values corresponding to each of the words is taken to obtain the target vector, which can be transformed using linear layers (or in general any suitable projection) to obtain the updated representation for the word \(bat\). This updated representation is often referred to as the contextual representation. The contextual representations are parallely calculated for each of the words in the sequence.
Mathematically, for a sequence of words \(\mathbb{x}\),
\[\textbf{key: } f(\mathbb{x}) = W_f\mathbb{x}\] \[\textbf{query: } g(\mathbb{x}) = W_g\mathbb{x}\] \[\textbf{value: } h(\mathbb{x}) = W_h\mathbb{x}\]Where, \(W_f\), \(W_g\) and \(W_h\) are projection layers shared across words. Assuming that the relevance scores are calculated using dot-product attention,
\[\alpha_{i,j} = \mathrm{softmax}(f(x_i)^Tg(x_j))\] \[o_j = W_v\left(\displaystyle\sum_{i=1}^{N}\alpha_{i,j}h(x_i)\right)\]\(o_j\) is the contextual representation of \(j\)th word in the sequence.
It is interesting to see, how the contextual representation is better than just a transformation using fully connected layers. The word \(bat\) can have several meanings for example the bird or as the verb to refer to the action of batting. The context however constrains the meaning to a cricket bat.
Self-Attention for Image Features
Zhang et al. used self-attention mechanism for convolutional feature maps. The following figure from the paper describes the setting.
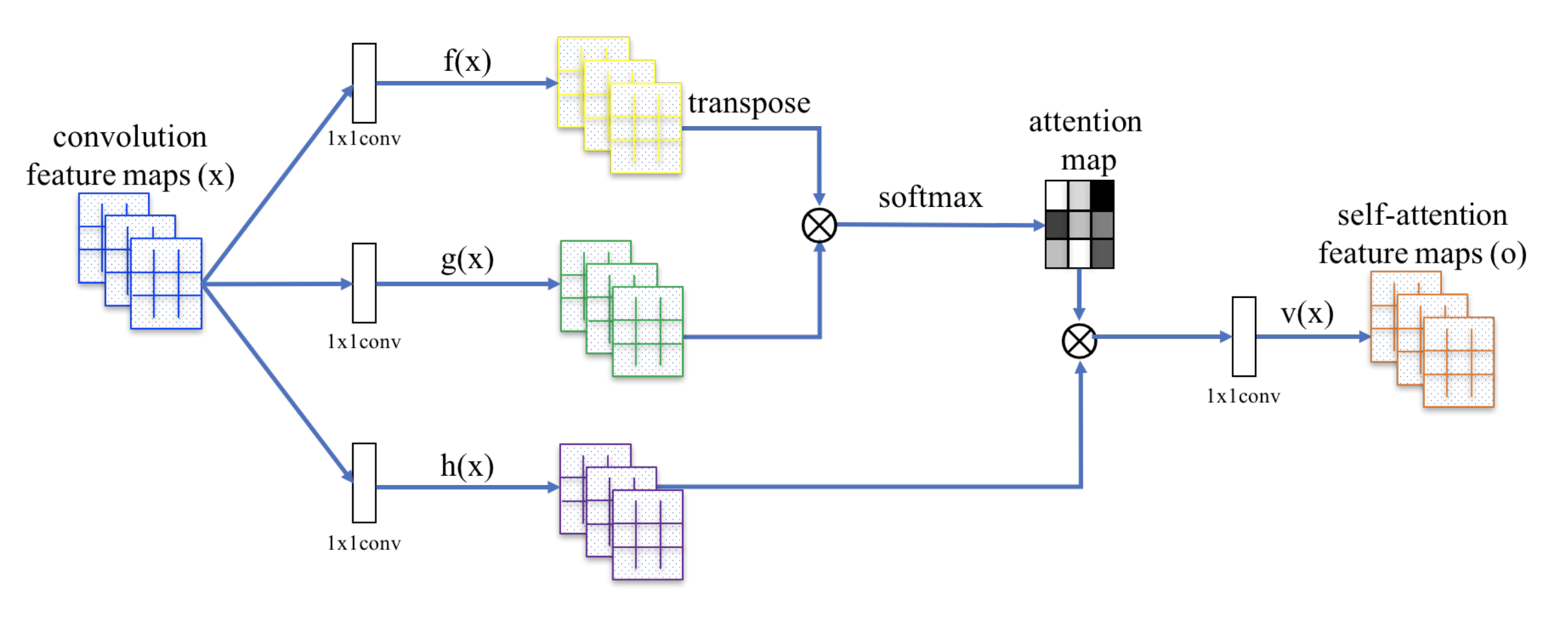
In this case, the linear sequence comprises of multiple feature maps. Each feature map in this sequence is analogous to a word in the sentence from the previous example. Each feature map is then projected into its corresponding query, key and value. \(1 \times 1\) convolution filters are used to project the feature map into query, key and value in order to retain the 2D structure of the feature map.
Mathematically, for an input sequence of feature map, \(\mathbb{x}\)
\[\textbf{key: } f(\mathbb{x}) = \mathbb{W}_f\mathbb{x}\] \[\textbf{query: } g(\mathbb{x}) = \mathbb{W}_g\mathbb{x}\] \[\textbf{value: } h(\mathbb{x}) = \mathbb{W}_h\mathbb{x}\]Similar to the case of sentences, the convolution filters used for projection into query, key and value triplets are shared across feature maps. This allows attention mechanisms to handle input feature maps of varying depths. Next, the dot product of query and key is take to determine the relevance scores which collectively are often referred to as the attention maps.
\[\alpha_{i,j} = \mathrm{softmax}(f(x_i)^Tg(x_j))\] \[o_j = \mathbb{W}_v\left(\displaystyle\sum_{i=1}^{N}\alpha_{i,j}h(x_i)\right)\]Features captured by a single feature map might make more sense when viewed with features captured by other feature maps. Self-attention helps to find feature representations that are aware of features captured by other feature maps. In this way, attention methods in images help to capture global dependencies in images.
Cross-Attention: An Overview
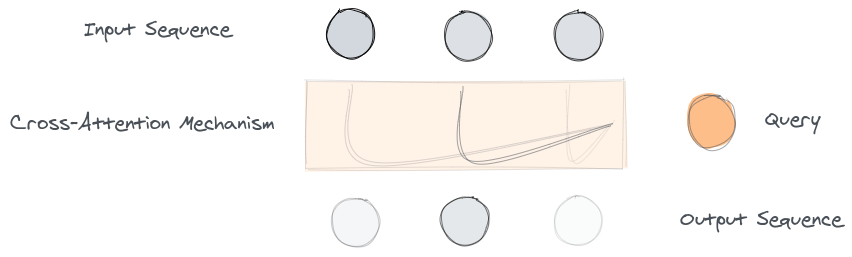
Suppose you have an image and a question related to the image. The image is a rich source of information and can be used to answer a lot of questions, however, a single question might require only a chunk of information from the image to be answered. The question is required to find out the relevant regions from the image that can help to find it’s answer.
You can use an attention mechanism to find the relevant regions. The query for the attention mechanism can be derived from the question and the key, value pairs from the image. Because of different sources of query and key, value pairs, the attention mechanism is called cross-attention.
Cross-Attention mechanisms are popular in multi-modal learning, where a decision is made on basis on inputs belonging to different modalities, often vision and language. Visual Question Answering is one of the established tasks in vision and language multi-modal learning. Others include visual commonsense reasoning, referring expression comprehension and visual entailment. Next, we see an example of cross attention for visual question answering. This should help in provinding a better insight on how are these mechanisms utilised and what advantages do they offer.
Cross-Attention in Visual Question Answering
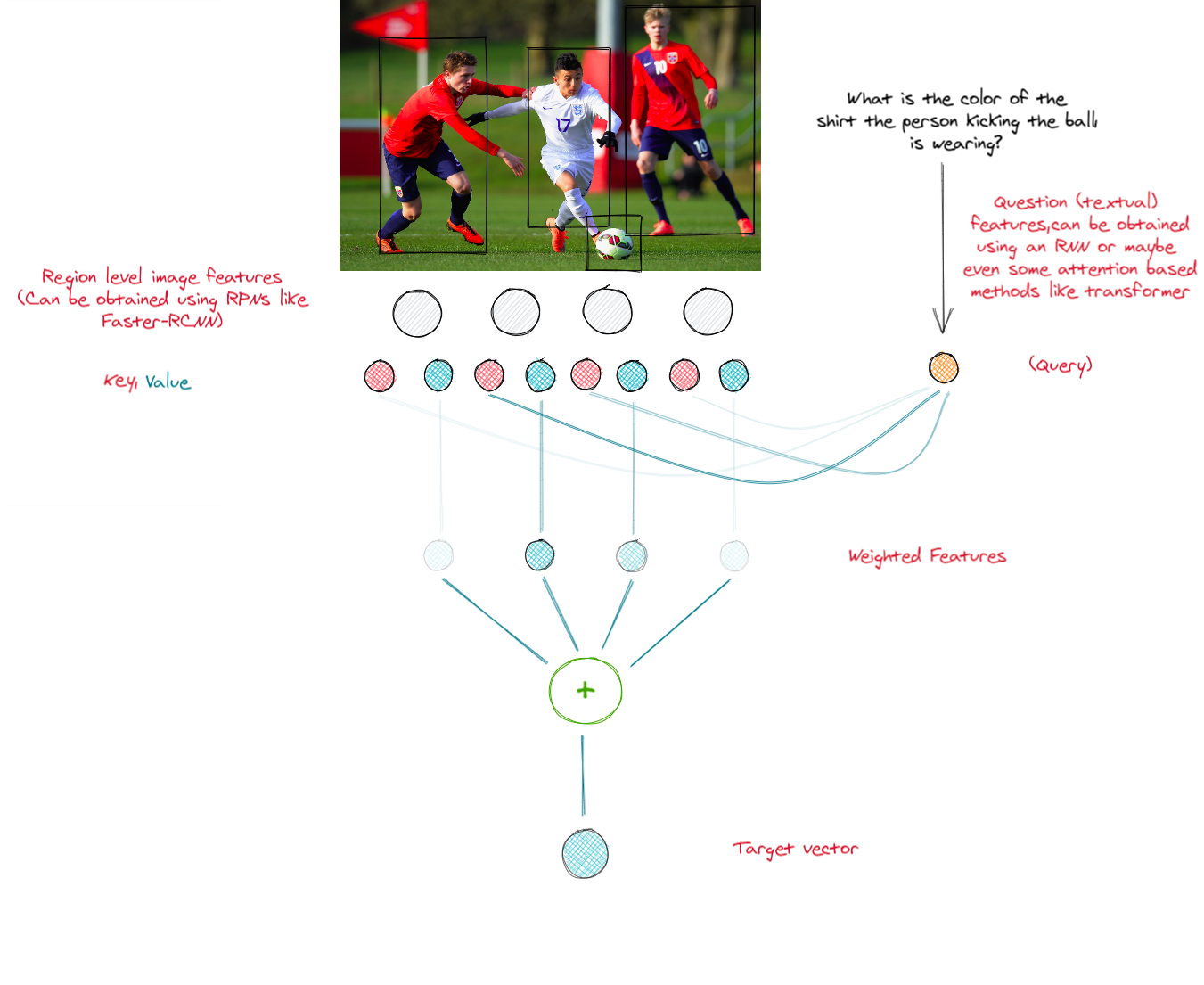
First of all, features are extracted from both the image and the question. Region level features for image can be extracted using networks like Faster-RCNN. For question (textual) features, an LSTM or an attention based method like transformer (which we shall discuss later) can be used. The feature vector for question acts as the query and the key, value pairs can be obtained by projecting region features.
The attention mechanism returns a single vector containing the relevance scores for each of the regions. A weighted sum can be taken to find the target vector containing the representation of image with relevant features. Usually, this target vector is transformed using a multi-layered perceptron to find the final representation of the image. The final representation of the image combined with the question features can then be used to answer the question.
Mathematically, for \(N\), regions each with a feature vector of size \(d_v\), combinedly represented as \(\mathbb{v} \in \mathbb{R}^{N \times d_v}\) and a question with feature vector \(q \in \mathbb{R}^{d}\),
\[\textbf{key: } f(\mathbb{v}) = \mathbb{W}_f\mathbb{v}\] \[\textbf{value: } g(\mathbb{v}) = \mathbb{W}_g\mathbb{v}\]Where \(W_f\) and \(W_g\) are chosen such that the resulting vector has a dimension \(d\). A relevance function \(O\) which can be either dot product or additive attention function is used to find the relevance of each region.
\[\mathbb{\alpha} = O(f(\mathbb{v}), q)\] \[\mathbb{v}' = \mathbb{\alpha}^Tg(\mathbb{v})\]\(\mathbb{v}'\) is the final representation of image that contains the features relevant to the question.
In the next part of this series, we will look into the details of multi-head attention and graph attention networks.
References
- Zhang, H., Goodfellow, I., & Metaxas, A. (2018). Self-Attention Generative Adversarial Networks arXiv e-prints, arXiv:1805.08318.
- Agrawal, A., Lu, J., Antol, M., Zitnick, C., & Batra, D. (2015). VQA: Visual Question Answering arXiv e-prints, arXiv:1505.00468.
Cited as:
@article{nikhil_attention,
title={Attention! An Other Perspective},
url={https://learningturtle.github.io/Blog/posts/attention_another_perspective_part2/},
journal={Learning Turtle},
author={Nikhil},
year={2020}
}
Postscript
If you find any mistakes/complicacies in our blogs or if you have any suggestions/feedback, do not hesitate to contact us at learningturtle.yt@gmail.com.